The basic TPA architecture has been implemented following the Beliefs, Desires and Intentions (BDI) paradigm [10], and using the University of Michigan Procedural Reasoning System (UM-PRS) platform [7]. This approach was deemed appropriate because of the type of tasks we expect a TPA to perform. Namely, a TPA has to be able to act in both an event-driven manner (e.g. when an UIA sends it a task to perform), and in a goal-driven fashion (e.g. it will always have the goals of ``learning more about the other agents'' and we hope to implement other learning mechanisms that will allow the TPA to modify its plans to better fit the current environment). A TPA will also need to dynamically switch between plans for achieving one goal versus another as when, for example, a goal is posted that has higher priority than the one the TPA is currently working on. We also wanted a TPA to be pro-active so that it could actively search for other agents that might help it carry out its task, and not just wait for them to come to him.
UM-PRS also allows the programmer to write simple sequential procedures to achieve the necessary goals, while the UM-PRS scheduler worries about when to execute them, when to preempt them for another higher priority event, and when to reinstate them. A good example of this is the get-reply goal. A common occurrence is for the TPA to send a message to another agent and then wait for a reply for some amount of time before timing out. In UM-PRS, the programmer can instruct the system to achieve the goals send-message and get-reply in sequence, as part of, say, some higher-level goal. The system will try to achieve them as such but, since the second one requires that the reply message has actually arrived, the system will block on this goal until the message does arrive. During this time, the system will not sit idly waiting but, if it has other goals that have been blocked or are merely waiting to be executed, (e.g. another message comes in, there are messages that need to be deleted from memory, etc.) it will change its focus of attention and start (or continue) to try to achieve them. Similarly, it will later return and handle the reply when it finally arrives. In the same vein, we could also send several messages and work on local tasks while waiting for the replies , automatically handling each reply in the order in which it comes in.
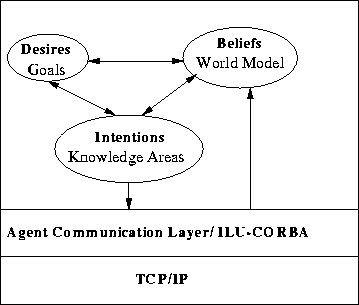
Figure 2: Diagram of the TPA architecture. Messages from other agents
go through the communications layers and become part of the agent's
world model. The communication layer is implemented using the
Inter-Language Unification (ILU) system [1],
which is compatible with the Common Object Request Broker Architecture
(CORBA). The agent's knowledge areas are responsible for generating
the messages to other agents.
The levels of our TPA architecture can be seen in Figure 2. The TPA communicates asynchronously with a communication layer which is responsible for the low-level message handling. The messages that arrive from other agents pass through the communications layer and are posted into the TPA's world model (i.e. they become part of the TPA's beliefs). If the message is a new task, then the TPA will immediately generate a top-level goal of achieving it. Otherwise the message has to be a reply to some previously sent message, which means that there are already active goals in the TPA that will trigger actions based on this reply. In the event that the message is neither a new task nor an expected reply, it is marked for deletion.
When using the BDI paradigm, one must decide between a myriad of intention semantics (i.e. what does it mean to intend something? when do intentions happen? when are they retracted? etc.). In UM-PRS, the intention semantics are summarized using a numerical priority and a selection function. We chose to use a simple selection function that basically states that, among the Knowledge Areas (KAs) that match the TPAs goals and beliefs, the one with the highest priority is always intended. When executing, the intended KA provides a blueprint for action, specifying what the TPA should do to achieve its goals within the current context of beliefs.
This simple method for prioritizing action selection can easily lead to a very messy control structure, one where the programmer loses track of the expected behavior of the agent (as can also occur in blackboard architectures, which have a similar control paradigm). In order to alleviate this problem, we also chose to divide the goals along three priority levels, (low, medium, high) and two achievability types (persistent and immediate). Persistent goals are those that are never achieved. For example, the garbage-collect goal finishes executing when there are no more messages left to collect. However, the goal is never achieved because there is always the possibility that new messages will arrive. Immediate goals, on the other hand, will eventually be, either achieved or will fail. We find that we can fit all of the type of goals we want the agent to achieve into one of the categories formed by these two dimensions, as seen here:
| Low | Medium | High | |
| Immediate | find-other-agents | do-task | |
| Persistent | garbage-collect | opportunistic-goals | |
| learning | dispatch-new-msgs |
The do-task goals are activated when a task comes in, and they form the basic behavior of the TPA. The garbage-collect and learning goals are done whenever the agent is not busy carrying out a task. Sometimes, while trying to achieve a task, the TPA might realize that the agents it thought existed to carry out a certain goal are no longer available or reachable. In these cases, the TPA will set up a find-other-agents goal that will, when there is time, try to find the desired agents (i.e. ask the registry for the specific agent types). As we mentioned, the dispatch-new-msgs goal deals with new incoming messages, it determines their priority and instantiates other do-task goals if necessary. The opportunistic goals activate KAs that can recognize a specific problem and provide a quick way of solving it, e.g. recognizing that a query will match a particular CIA and adding it to the result set. They are a good way of implementing either learned knowledge or quick shortcuts. The division of the priorities into three classes does not rule out the use of much more fine-grained priority values. In fact, we believe that continuous priorities will be very useful, as long as they stay within the limits dictated by the coarser division.
Thus, our TPA architecture supports both pro-active and reactive agent behavior, based on internalized goals and beliefs of the agent. In contrast to other ``simpler'' agents that could be in the UMDL--agents which are purely reactive and sit idle until asked to service a specific request--our TPA architecture provides general functionality for integrating persistent, adaptable agents within the UMDL. We therefore expect our architecture to be widely applicable to various task planning, and other knowledge-based, services that must be an integral part of a successful large-scale digital library.
![]()
![]()
![]()
![]()
Next: TPA language
Up: Task Planner Agent
Previous: Task Planner Agent