This talk provides a quick overview of XML parsing using Java
import java.io.FileReader;
import org.xml.sax.XMLReader;
import org.xml.sax.Attributes;
import org.xml.sax.InputSource;
import org.xml.sax.helpers.XMLReaderFactory;
import org.xml.sax.helpers.DefaultHandler;
/** Our handler must extend DefaultHandler */
public class MySAXApp extends DefaultHandler
{
public static void main (String args[])
throws Exception
{
XMLReader xr = XMLReaderFactory.createXMLReader();
MySAXApp handler = new MySAXApp();
xr.setContentHandler(handler);
xr.setErrorHandler(handler);
for (int i = 0; i < args.length; i++) {
FileReader r = new FileReader(args[i]);
xr.parse(new InputSource(r));
}
}
public MySAXApp ()
{
super();
}
public void startDocument ()
{
System.out.println("Start document");
}
public void endDocument ()
{
System.out.println("End document");
}
/**
* Receive notification at the beginning of an element.
*
* @param uri The Namespace URI, or the empty string if the element
has no Namespace URI or if Namespace processing is not being
performed.
* @param name The local name (without prefix), or the empty string
if Namespace processing is not being performed.
* @param qName The qualified name (with prefix), or the empty
string if qualified names are not available.[namespaceprefix:name]
* @param atts The attributes attached to the element. If there are
no attributes, it shall be an empty Attributes object.
*/
public void startElement (String uri, String name,
String qName, Attributes atts)
{
if ("".equals (uri))
System.out.println("Start element: " + qName);
else
System.out.println("Start element: {" + uri + "}" + name);
}
public void endElement (String uri, String name, String qName)
{
if ("".equals (uri))
System.out.println("End element: " + qName);
else
System.out.println("End element: {" + uri + "}" + name);
}
/**
* Receive notification of character data.
*
* @param ch[] The characters from the XML document.
* @param start The start position in the array.
* @param length The number of characters to read from the array
*/
public void characters (char ch[], int start, int length)
{
System.out.print("Characters: \"");
for (int i = start; i < start + length; i++) {
switch (ch[i]) {
case '\\':
System.out.print("\\\\");
break;
case '"':
System.out.print("\\\"");
break;
case '\n':
System.out.print("\\n");
break;
case '\r':
System.out.print("\\r");
break;
case '\t':
System.out.print("\\t");
break;
default:
System.out.print(ch[i]);
break;
}
}
System.out.print("\"\n");
}
}
- Given the following XML file as input
<?xml version="1.0"?>
<poem xmlns="http://www.megginson.com/ns/exp/poetry">
<title>Roses are Red</title>
<l>Roses are red,</l>
<l>Violets are blue;</l>
<l>Sugar is sweet,</l>
<l>And I love you.</l>
</poem>
- Using the command-line argument (replace
com.example.xml with the implementation you are
using):
java
-Dorg.xml.sax.driver=com.example.xml.SAXDriver MySAXApp
roses.xml- It will print out:
Start document
Start element: {http://www.megginson.com/ns/exp/poetry}poem
Characters: "\n"
Start element: {http://www.megginson.com/ns/exp/poetry}title
Characters: "Roses are Red"
End element: {http://www.megginson.com/ns/exp/poetry}title
Characters: "\n"
Start element: {http://www.megginson.com/ns/exp/poetry}l
Characters: "Roses are red,"
End element: {http://www.megginson.com/ns/exp/poetry}l
Characters: "\n"
Start element: {http://www.megginson.com/ns/exp/poetry}l
Characters: "Violets are blue;"
End element: {http://www.megginson.com/ns/exp/poetry}l
Characters: "\n"
Start element: {http://www.megginson.com/ns/exp/poetry}l
Characters: "Sugar is sweet,"
End element: {http://www.megginson.com/ns/exp/poetry}l
Characters: "\n"
Start element: {http://www.megginson.com/ns/exp/poetry}l
Characters: "And I love you."
End element: {http://www.megginson.com/ns/exp/poetry}l
Characters: "\n"
End element: {http://www.megginson.com/ns/exp/poetry}poem
End document
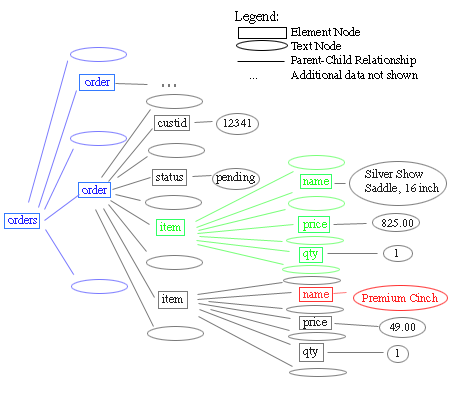
- A DOM
Document is a hierarchy (tree) of nodes
- The following XML file:
<?xml version="1.0" encoding="UTF-8"?>
<orders>
<order>
<customerid limit="1000">12341</customerid>
<status>pending</status>
<item instock="Y" itemid="SA15">
<name>Silver Show Saddle, 16 inch</name>
<price>825.00</price>
<qty>1</qty>
</item>
<item instock="N" itemid="C49">
<name>Premium Cinch</name>
<price>49.00</price>
<qty>1</qty>
</item>
</order>
<order>
<customerid limit="150">251222</customerid>
<status>pending</status>
<item instock="Y" itemid="WB78">
<name>Winter Blanket (78 inch)</name>
<price>20</price>
<qty>10</qty>
</item>
</order>
</orders>
- Is represented by a tree like:
- Notice all the text nodes. They are there because there
is whitespace in between all tags.
- Our goal is to get a
Document object that
represents our XML file. Since Document is an
interface we must use a factory.
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import java.io.File;
import org.w3c.dom.Document;
public class OrderProcessor {
public static void main (String args[]) {
File docFile = new File("orders.xml");
Document doc = null;
try {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
doc = db.parse(docFile);
} catch (Exception e) {
System.out.print("Problem parsing the file.");
}
}
}
- In order to traverse the Document we first need to get the
root element.
- We do this with a
doc.getDocumentElement()
call.
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import java.io.File;
import org.w3c.dom.*;
public class OrderProcessor {
public static void main (String args[]) {
doc = db.parse(docFile);
Element root = doc.getDocumentElement();
System.out.println("The root element is "+root.getNodeName());
NodeList children = root.getChildNodes();
System.out.println("There are "+children.getLength()
+" nodes in this document.");
for (Node child = root.getFirstChild();
child != null;
child = child.getNextSibling())
{
System.out.println(child.getNodeName()+" = "+child.getNodeValue());
}
stepThrough(root);
}
private static void stepThrough (Node start)
{
System.out.println(start.getNodeName()+" = "+start.getNodeValue());
if (start.getNodeType() == start.ELEMENT_NODE)
{
NamedNodeMap startAttr = start.getAttributes();
for (int i = 0;
i < startAttr.getLength();
i++) {
Node attr = startAttr.item(i);
System.out.println(" Attribute: "+ attr.getNodeName()
+" = "+attr.getNodeValue());
}
}
for (Node child = start.getFirstChild();
child != null;
child = child.getNextSibling())
{
stepThrough(child);
}
}
}
- With DOM we can change the
Document in any way
we want.
public class OrderProcessor {
/** Change the value of node elemName to elemValue */
private static void changeOrder (Node start,
String elemName,
String elemValue)
{
if (start.getNodeName().equals(elemName)) {
start.getFirstChild().setNodeValue(elemValue);
}
for (Node child = start.getFirstChild();
child != null;
child = child.getNextSibling())
{
changeOrder(child, elemName, elemValue);
}
}
public static void main (String args[]) {
changeOrder(root, "status", "processing");
NodeList orders = root.getElementsByTagName("status");
for (int orderNum = 0;
orderNum < orders.getLength();
orderNum++)
{
System.out.println(orders.item(groupNum).getFirstChild().getNodeValue());
Element thisOrder = (Element)orders.item(orderNum);
Element customer = (Element)thisOrder.getElementsByTagName("cusomertid").item(0);
customer.removeAttribute("limit");
NodeList orderItems = thisOrder.getElementsByTagName("item");
double total = 0;
for (int itemNum = 0;
itemNum < orderItems.getLength();
itemNum++) {
Element thisOrderItem = (Element)orderItems.item(itemNum);
if (thisOrderItem.getAttributeNode("instock").getNodeValue().equals("N")) {
Node deadNode = thisOrderItem.getParentNode().removeChild(thisOrderItem);
continue;
Element backElement = doc.createElement("backordered");
backElement.setAttributeNode(doc.createAttribute("itemid"));
String itemIdString = thisOrderItem.getAttributeNode("itemid").getNodeValue();
backElement.setAttribute("itemid", itemIdString);
Node deadNode = thisOrderItem.getParentNode()
.replaceChild(backElement, thisOrderItem);
}
String thisPrice = thisOrderItem.getElementsByTagName("price").item(0)
.getFirstChild().getNodeValue();
double thisPriceDbl = new Double(thisPrice).doubleValue();
String thisQty = thisOrderItem.getElementsByTagName("qty").item(0)
.getFirstChild().getNodeValue();
double thisQtyDbl = new Double(thisQty).doubleValue();
double thisItemTotal = thisPriceDbl*thisQtyDbl;
total = total + thisItemTotal;
}
String totalString = new Double(total).toString();
Node totalNode = doc.createTextNode(totalString);
Element totalElement = doc.createElement("total");
totalElement.appendChild(totalNode);
thisOrder.insertBefore(totalElement, thisOrder.getFirstChild());
}
}
}
- Going from a a
Document to its XML
representation only requires calling toString() on
it.
- A normalized XML document has no extraneous
whitespace.
- In order to normalize your document call
normalize() on it.
- To be complete your document will need the <?xml....>
and <!DOCTYPE...> lines, these can be added:
try
{
File newFile = new File("processedOrders.xml");
FileWriter newFileStream = new FileWriter(newFile);
newFileStream.write("<?xml version=\"1.0\"?>");
newFileStream.write("<!DOCTYPE "+doc.getDoctype().getName()+" ");
if (doc.getDoctype().getSystemId() != null)
{
newFileStream.write(" SYSTEM ");
newFileStream.write(doc.getDoctype().getSystemId());
}
if (doc.getDoctype().getPublicId() != null)
{
newFileStream.write(" PUBLIC ");
newFileStream.write(doc.getDoctype().getPublicId());
}
newFileStream.write(">");
newFileStream.write(newRoot.toString());
newFileStream.close();
} catch (IOException e) {
System.out.println("Can't write new file.");
}
- We catch the errors by implementing an error handler and passing it to the parser.
- The error handler must extend
DefaultHandler.
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.SAXParseException;
/** A simple error handlier which just prints out
the errors. */
public class ErrorChecker extends DefaultHandler
{
public ErrorChecker() {
}
public void error (SAXParseException e) {
System.out.println("Parsing error: "+e.getMessage());
}
public void warning (SAXParseException e) {
System.out.println("Parsing problem: "+e.getMessage());
}
public void fatalError (SAXParseException e) {
System.out.println("Parsing error: "+e.getMessage());
System.out.println("Cannot continue.");
System.exit(1);
}
}
- The code to run the validating parser looks like:
import org.apache.xerces.parsers.DOMParser;
import java.io.File;
import org.w3c.dom.Document;
public class SchemaTest {
public static void main (String args[]) {
File docFile = new File("memory.xml");
try {
DOMParser parser = new DOMParser();
parser.setFeature("http://xml.org/sax/features/validation", true);
parser.setProperty(
"http://apache.org/xml/properties/schema/external-noNamespaceSchemaLocation",
"memory.xsd");
ErrorChecker errors = new ErrorChecker();
parser.setErrorHandler(errors);
parser.parse("memory.xml");
} catch (Exception e) {
System.out.print("Problem parsing the file.");
}
}
}