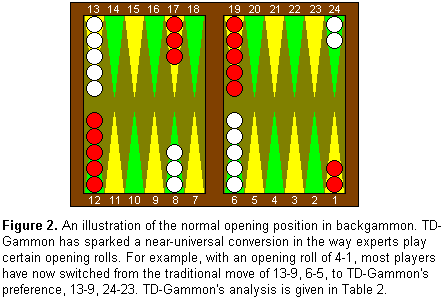
←
^
→
Reinforcement Learning
TD-Gammon
The
TD-Gammon
system learned to play championship Backgammon by playing 1.5 million games against itself.
It received an immediate reward for +100 for a win, -100 for a loss.
Equal to the best human.
José M. Vidal
.
3 of 22