Internet Basics and HTML
CSCE 242
University of South Carolina
José M. Vidal [1]
http://jmvidal.cse.sc.edu/talks/internet/ [2]
This talks provides a brief history of the Internet and
distributed applications. For more information read:
1 Timeline

| Year |
Event |
| 1970 |
Work on Unix begins. VT 05 introduced.
|
| 1971 |
First FTP and Telnet implementations. |
| 1973 |
TCP development begins. |
| 1978 |
VT 100 introduced. |
| 1982 |
Sun founded (now).
Sun 1 |
| 1983 |
BSD Unix ships TCP-IP stack. TCP-IP becomes a government standard. Sun hires Schmidt . [4] |
| 1984 |
Work begins on X-windows. X terminal. Apple MacIntosh. Steves, with stache |
| 1985 |
MS Windows, Founders, Gates, modeling. |
| 1989 |
Object Management Group founded. |
| 1990 |
Object Linking and Embedding (OLE).
COM provided infrastructure.
Tim Berners-Lee develops WWW. |
| 1991 |
CORBA 1.1 released. |
| 1992 |
Internet opened to commercial traffic. |
| 1993 |
Mosaic released. |
| 1994 |
Netscape navigator released. Yahoo |
| 1995 |
CORBA 2.0 released. IIOP standardized. Gosling introduces Java. |
| 1996 |
COM is renamed ActiveX. Brin and Page develop Backrub, in a tub?. Hotmail. |
| 1997 |
Java RMI (JDK 1.1). |
| 1998 |
DCOM. Google. XML 1.0. |
| 1999 |
RSS. Netscape dies. |
| 2000 |
Microsoft announces .NET initiative.
Chooses SOAP for distributed programming. |
| 2003 |
del.icio.us |
| 2004 |
Gmail, Firefox |
| 2005 |
Ajax coined |
Note:
The history of the Internet is interlaced with the history
of Unix as it was on Unix that all the early tools (programs)
for inter-machine communication were developed. First we saw
tools for transferring data from one machine to another as that
was the most pressing need. Once you could transfer data, it was
a simple matter to make this data a text file and call it
email. Programs first began to talk to each other using Remote
Procedure Calls (RPC). RPCs are a simple extension on functional
languages which, at that time, were dominant. As object-oriented
languages (OOLs) became popular, with the advent of C++, the
programmers needed a way to do what RPC did, but with an
OOL. This need ushered lead the development of CORBA. Later on,
Java re-implemented the same ideas, but in a simplified manner,
in Java RMI.
Microsoft's OS was only used in low-end personal computers
which were rarely networked. As such, it largely ignored these
developments. However, Microsoft faced another problem, it
needed to develop a way for many programs to share the same
functionality without having it replicated in each
program. That is, it needed shared libraries which they named
Dynamic Link Libraries (DLL). DLLs were used to create
components which were tied together by following specific
guidelines, a process dubbed Object Linking and Embedding
(OLE). OLE went thru several revisions and was then renamed
COM. COM is a component model which allows one component to be
used by other programs running in the same machine. Microsoft
realized that they could add some networking infrastructure
and distribute the invocation of component, and idea that gave
rise to Distributed COM (DCOM). DCOM is very complicated to
learn and many programmers shun it. In 2000 Microsoft
announced the .NET initiative which replaces all the
functionality of DCOM with a much simpler system based on open
standards.
1.1 The Future
 [5]
[5]
- More webapps.
- Local-remote distinction disappears.
- Multiple frontends: desktop, netbook, mobile, voice.
- Semantic markup.
2 Abstraction Layers
| Application. |
|
Application. |
| Transport. TCP, UDP. |
|
Transport. TCP, UDP. |
| Internet. IP. |
|
Internet. IP. |
| Host-to-network. Ethernet, FDDI. |
- The Open Systems Interconnection (OSI) 7-level model is
overkill since many layers collapse into one or don't
exist.
- Host-to-network defines how a particular network
interface (Ethernet card, PPP connection) sends IP datagrams
over its physical connection. Examples: Ethernet, Token Ring,
LocalTalk.
- A gateway can convert from one interface to
another.
Note:
In this class we will focus on the application layer.
3 TCP/IP
- The Internet Layer breaks data into
datagrams. Examples: IP, AppletTalk, NetBEUI.
- Each datagram (packet) is sent independently of the others
and travels the Internet on its own path [6].
| 0 |
4 |
8 |
12 |
16 |
20 |
24 |
28 |
| Version |
Header Length |
Type of Service |
Datagram Length |
| Identification |
Flags |
Fragment Offset |
| TTL |
Protocol |
Header checksum |
| Source address IP |
| Destination address IP |
| Options |
| TCP: Source Port |
TCP: Destination Port |
| TCP: Sequence Number |
| TCP: Acknowledgment Number |
Function of the bits in an IP datagram packet, using TCP.
Note:
Of course, you do not need to memorize the particular bit
positions. However, it is important to know what information
is stored in a packet since this tells you what can and cannot
be done at the network layer. For example, at the network
layer one cannot filter on content (data) without also knowing
how the content is represented.
3.1 TCP and UDP
- The transport layer is implemented by either TCP or UDP.
- The Transmission Control Protocol make sure that
all packets are received, and in order. It uses numbering
and re-sending. RFC 761 [7]
- User datagrams allow lost and unordered
packets. It is thus faster than TCP. RFC 768 [8]
4 Firewalls and Proxies
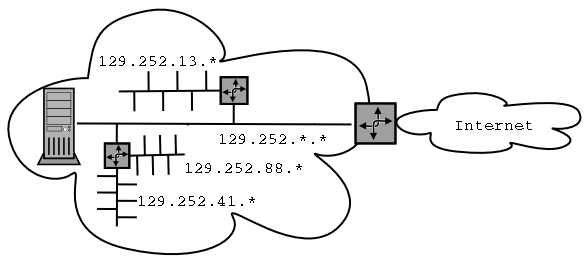
- A router sits between two networks and routes packets
between them by looking at the destination IP address. It knows
which numbers are "left" and which are "right".
- A firewall is like a router but it can decide not to
route certain packets. It often looks at the port when
making a decision (e.g., block all telnet connections).
- Most companies place a firewall between them and the
Internet.
- A proxy is a go-between. Outside machines don't see
the IP of machines inside. It works at the application
level. e.g., Internet Object cache.
- In a client-server architecture the server provides
services which the client consumes (e.g.,
browser-webserver).
- An n-tier architecture expands this concept to
multiple levels (e.g., browser-webserver-database).
Note:
We care about firewalls mostly when they prevent us from
deploying a distributed program. If you are building a large
distributed system you will need to coordinate with the
network administrators to make sure that all the packets can
get thru at all times.
5 DNS
- Domain Name System (DNS) resolves host names
(e.g. jmvidal.cse.sc.edu) into their corresponding IP numbers
(129.252.11.88). It is described in a series of RFCs [9].
- IP numbers relate to the physical layout of the
network. They are used for routing.
- It is hierarchical. Each domain (sc.edu) has its own
authority. If it does not know the mapping it will ask a higher
domain (.edu) ending in one of the eight root DNS servers. Fro
example:
- When your machine
hadar.cse.sc.edu needs to
know the IP for www.wastingtime.com it will ask
your local DNS server (cse). If it does not have it cached, it
will ask the next one higher up (sc).
- Domain names relate to ownership and responsibility. They
are meant to be used by humans.
5.1 Whois
- In Unix the
whois command can be used to get
ownership information:
whois sc.edu [10]
Registrant:
University of South Carolina (SC6-DOM)
1244 Blossom Street
Columbia, SC 29208
US
Domain Name: SC.EDU
Administrative Contact:
Yarbrough, Stan (SY1779) syarb@GWM.SC.EDU
University of South Carolina
1244 Blossom Street
Columbia, SC 29208
803-777-7474 (FAX) 803-777-1900
Technical Contact:
Mowery, Bill (BM13149) bill.mowery@SC.EDU
University of South Carolina
514 Main Street
Columbia, SC 29208
803-777-4636 (FAX) 803-777-8644
Billing Contact:
Wider, Ella (EW1183) wider-ella@SC.EDU
USC DLIS
Thomas Cooper Library
Columbia, SC 29208
(803) 777-2498
Record last updated on 14-Dec-2001.
Record created on 07-Mar-1995.
Database last updated on 26-Dec-2001 23:14:00 EST.
Domain servers in listed order:
THEUSC.CSD.SC.EDU 129.252.41.11
SPARKY.CSD.SC.EDU 129.252.42.25
6 Internet Services
- Each host can establish a different connection on one of its
ports. There are 65536 ports. Some are reserved:
- telnet: 23
- http: 80
- ftp: 21
- smtp: 25
- A class C address reserve the first 3 bytes (e.g.,
199.1.2.*), while a class B reserves the first two (e.g.,
127.1.*.*).
- 10.*.*.*, 172.1.*.*, 172.31.*.*, 192.168.*.* are
nonroutable.
- 127.*.*.* is the loopback number.
- We are running out of IP numbers. IPv6 will add more bytes.
7 Example
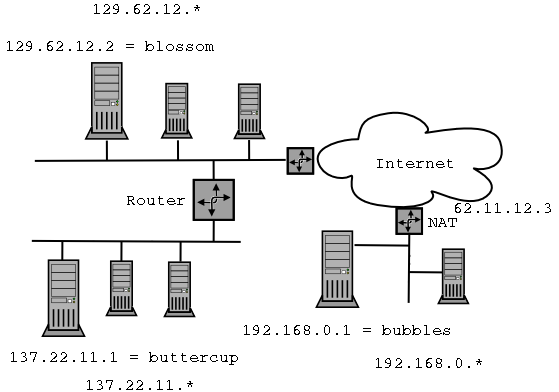
- Blossom wants to send a packet to buttercup at port 80.
- Blossom queries the local DNS server for buttercup's IP address.
- Blossom broadcasts an IP datagram with destination address of
137.22.11.1 on the local Ethernet.
- No other computer on the local Ethernet reads the packet
because its not addressed to them (unless they are running a
sniffer).
- The router recognizes that this IP will not find its
destination of that subnet. It the re-broadcasts the packet
on the appropriate sub-net. The source and destination fields
are kept the same.
- Buttercup sees the packet addressed to it and reads
it.
- Blossom wants to send a packet to bubbles on port 25.
- Bubbles does not have a real IP number, so it does not
exist on the Internet.
- Blossom somehow (offline) determines that it should
instead send a packet to 62.11.12.3. on port 25, hoping that
the NAT will do
the right thing.
- Repeat the first four steps of the previous scenario,
except that this time the other router picks it up and
forwards it to the Internet.
- The packet goes thru any number of routers on the
Internet until it is seen by 62.11.12.3 who then changes the
destination IP of the packet to 198.169.0.1 and places it on
the local subnet.
- Bubbles sees the modified packet and reads it.
Note:
The computers "outside" an NAT see it as just one
machine. The computers inside the NAT think that they are on
the open Internet. The NAT has the job of remembering who on
the inside is talking to who on the outside and re-write the
Destination-IP fields of all the packets.
One drawback of using an NAT is that a computer on the
outside cannot make first contact with a computer on the
inside, computers on the outside can only reply to messages
sent from the inside. That is unless the NAT is set up to
specifically forward new packets to some machine inside. For
example, it could be set up to forward all new packets to
port 80 to a particular machine which servers as the
company's web server.
8 Internet Standards
| Internet Engineering Task Force (IETF [11]) |
World Wide Web Consortium (W3C [12]) |
| Democratic. Open to anyone. |
Vendor organization led by dues-paying corporations. |
| After-the-fact. Request for Comments (RFC) |
Before-the-fact. |
| TCP-IP, MIME, SMTP |
HTTP, HTML, XML, CSS |
- Experimental
- Proposed standard
- Draft standard
- Standard
- Informational- not required
- Historic- obsolete
|
- Note
- Working draft
- Candidate recommendation
- Proposed recommendation
- Recommendation
|
9 Uniform Resource Identifier
- The URI is defined in RFC 2396 [13].
- It looks like
scheme:scheme-specific part. For
example, the scheme part can be: data, file, ftp, http, gopher,
mailto, news, telnet, wais, etc. The scheme-specific part
usually looks like
//authority/path?query
- It can be further classified as either a location, a name, or
both.
- A Universal Resource Name (URN) is required to remain
globally unique and persistent even when the resource ceases to
exist or becomes unavailable. RFC 2141 [14].
urn:namespace:resource-name- For example:
urn:isbn:1234-98754-09
- Used by doi [15] system.
- A Universal Resource Locator (URL) identifies
resources via a representation of their primary access
mechanism. RFC
1738 [16].
protocol://username:password@host:port/path/file#fragment?query
10 HTML, SGML, and XML
- The Standard Generalized Markup Language (SGML) was
established in 1986 as an ISO standard for describing a text's
semantics, rather than its appearance.
- For example, saying that "The title of this document is
RFC 123", rather than "Center RFC 123 on this page with an
18pt bold font".
- SGML was championed by librarians and the publishing
industry.
- The idea was to have one source document which could
then be automatically transformed into many formats.
- SGML is a meta language. Over time it became very hard
to write a parser for it.
- The Hyper Text Markup Language (HTML) is an instance of
SGML.
- The eXtensible Markup Language (XML) is the W3C's effort to
create a new meta language that is simpler than SGML.
11 MIME
- The Multipurpose Internet Mail Extensions (MIME) standard is
defined in RCF 2045 [17].
- It was originally developed as a way to add (binary)
attachments to what was at the time only plain-text email.
- It has become a widely used technique for describing a
file's content.
- It supports almost a hundred predefined types of
content.
- Content types have a type, and a subtype. The type give a
general idea of what the data represents (e.g., a picture, a
video, a movie), which the subtype specifies the specific
encoding (e.g., gif, jpeg, mpeg). Some examples are:
- text/html
- text/plain
- image/gif
- image/jpeg
- MIME also allows the user to define non-standard types, by
prefixing them with an x-
- application/x-framemaker
- audio/x-wav
12 Hyper Text Transfer Protocol
- HTTP was originally defined in RFC 1945 [18]. HTTP
1.1 is in RFC
2616 [19].
- HTTP is a stateless protocol for fetching MIME-encoded
information from another machine in the Internet.
- The steps are:
- Make connection.
- Make request:
GET /index.html HTTP1.0
Accept: text/html, text/plain
User-Agent: Mozilla/1.0
\r\n
\r\n
A POST request can include data before the \r\n\r\n
.
- Get a response:
HTTP/1.1 200 OK
Date: Fri, 28 Dec 2001 14:59:11 GMT
Server: Apache/1.3.20 (Unix) PHP/4.0.6 mod_ssl/2.8.4 OpenSSL/0.9.6b
Last-Modified: Fri, 28 Dec 2001 14:55:00 GMT
ETag: "a5a99-17f5-3c2c87c4"
Accept-Ranges: bytes
Content-Length: 6133
Connection: close
Content-Type: text/html
\r\n
\r\n
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<HTML LANG="en"><HEAD>
<TITLE>University of South Carolina Home Page</TITLE></HEAD>
......
- Close connection.
- Closing the connection every time is costly. HTTP 1.1 does
not close the connection.
- Cookies are opaque strings that are sent by the browser to
the server based on its IP number.
- Under the Common Gateway Interface (CGI) the server rather
than returning the named file will run it as a program, passing
it the arguments and values in the URL path.
Note:
The fact that HTTP is stateless was both one of the reasons
for its widespread early adoption as well as one of the
biggest headeaches when using it for complex
applications. Because it is stateless it is very easy to
implement, so basic web servers could be written in a page of
code. However, it also means that if the user is involved in
an interaction that requires more than one step then some sort
of cheat must be used. The first attempts extended the URL
with state information. This created some large ugly URLs and
gave rise to problems if the user decided to bookmark that
URL. The next attempt was the standardization by Netscape of
Cookies.
12.1 HTTP Request Methods
- The line
GET /index.html HTTP1.0 is a
request, where GET is the method
- Some of the most common methods are:
| GET URI |
Retrieve information pointed to by URI. |
| HEAD URI |
Identical to GET but server must not return a message body. |
| POST URI data |
Request that the server accept the following data as a subordinate of the resource pointed to by URI. |
| PUT URI data |
Replace the data pointed to by URI with the following data |
| DELETE URI |
Delete the data pointed to by URI. |
- After the request line one can add any number of
request headers.
- Some of the most common headers are:
| Accept: |
Specify media types which are
acceptable for response (e.g. pdf, gif, png, flash, etc.)
Can also give ordered preferences using the
q quality value: 1 is most preferred, 0 is
least.
Accept: audio/*; q=0.2,
audio/basic |
| Accept-Charset: |
Specify what charsets are acceptable for response.
Accept-Charset: iso-8859-5, unicode-1-1;q=0.8 |
| Accept-Encoding: |
Restricts the content encodings that are acceptable.
Accept-Encoding: compress, gzip |
| Accept-Language: |
Restrict the language.
Accept-Language: da, en-gb;q=0.8, en;q=0.7 |
| Authorization: |
Include the credentials (username and password) needed to authenticate with the server. |
| From: |
Contains the email address of the human issuing the request.
From: president@whitehouse.gov |
| Host: |
Specifies the Internet host and port number of the resource being requested.
GET /pub/WWW/ HTTP/1.1
Host: www.w3.org |
| If-Modified-Since: |
Only return the document if it has been modified after the given date.
If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
| User-Agent: |
Specifies the user agent (web browser) being used.
Mozilla/4.0 (compatible; MSIE 5.5;Windows 98) |
12.3 HTTP Response
- The server returns a response which begins with
a status code number, such as 404: Page Not Found,
and 200: OK.
- There are 40 defined status codes.
- The response can also include any number of response headers
| Accept-Ranges: |
Server specifies its acceptance of range (parts of a file) requests.
Accept-Ranges: bytes. |
| Age: |
Time since the response was generated by the server. Useful for changing data such as weather and stock quotes. Age is in seconds.
Age: 600 |
| ETag: |
Value of the entity tag for the requested variant. ETags are meant to function as unique identifiers for documents. |
| Location: |
Used to re-direct the user to another location.
Location: http://www.w3.org/pub/WWW/People.html |
| Server: |
Information about the server.
Server: CERN/3.0 libwww/2.17 |
12.4 Cookies
- Cookies were added as headers later, they are defined in RFC 2109 [20].
- A cookie is a string.
- Server creates string and sends it to client in the respons
header.
- Client agrees to sent it back, in a request header, whenever it
goes back to that server.
13 CGI
- The Common Gateway Interface [21] is a method for
generating web pages dynamically.
- Instead of interpreting the argument of GET (or POST) as a
filename, its interpreted as a program name with arguments.
13.1 GGI URL
- The URL for a GET is interpreted as
programname?parameter1=value1¶meter2=value2&..... The
values are optional. The parameters and values are passed as
command-line arguments to the program.
- For a POST, all the parameters and values are passed to the
program in the standard input. That is, as thought a person had
first run the program and then typed the information on the
keyboard.
13.2 CGI Problems
- The program is run and whatever it prints out is sent back
to the client.
- CGI programs run as independent processes and so have many drawbacks:
- They consume a lot of system resources.
- They suffer from startup delays.
- It is hard to maintain state between successive calls
(must write to file).
14 Applets
15 References
 [22]
[22]

URLs
- José M. Vidal, http://jmvidal.cse.sc.edu
- http://jmvidal.cse.sc.edu/talks/internet/, http://jmvidal.cse.sc.edu/talks/internet/
- RFC 2616:, http://www.ietf.org/rfc/rfc2616.txt
- ., http://video.google.com/videoplay?docid=7365682421609020531
- http://www.swivel.com/graphs/show/24342294
- Comic Strip, http://ars.userfriendly.org/cartoons/?id=19990304
- RFC 761, http://www.ietf.org/rfc/rfc0761.txt
- RFC 768, http://www.ietf.org/rfc/rfc0768.txt
- series of RFCs, http://www.dns.net/dnsrd/rfc/
- whois sc.edu, http://www.whois.net/whois_new.cgi?d=sc.edu
- IETF, http://www.ietf.org/
- W3C, http://www.w3.org/
- RFC 2396, http://www.ietf.org/rfc/rfc2396.txt
- RFC 2141, http://www.ietf.org/rfc/rfc2141.txt
- doi, http://doi.org
- RFC
1738, http://www.ietf.org/rfc/rfc1738.txt
- RCF 2045, http://www.ietf.org/rfc/rfc2045.txt
- RFC 1945, http://www.ietf.org/rfc/rfc1945.txt
- RFC
2616, http://www.ietf.org/rfc/rfc2616.txt
- RFC 2109, http://www.faqs.org/rfcs/rfc2109.html
- CGI
Specifications, http://www.w3.org/CGI/
- http://www.amazon.com/gp/product/1565925092?ie=UTF8&tag=multiagentcom&linkCode=as2&camp=1789&creative=390957&creativeASIN=1565925092
- wikipedia:Hypertext_Transfer_Protocol, http://www.wikipedia.org/wiki/Hypertext_Transfer_Protocol
This talk available at http://jmvidal.cse.sc.edu/talks/internet/
Copyright © 2009 José M. Vidal
.
All rights reserved.
19 December 2008, 03:27PM
