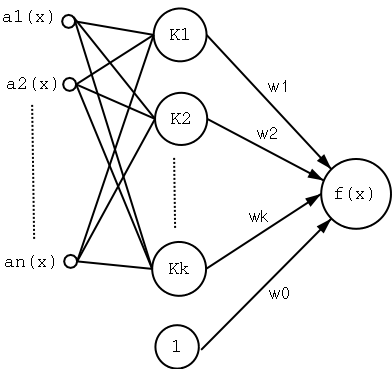
Radial Basis Function Networks
- We can view the new $\hat{f}(x)$ as a two-layer network
were the first layer computes the various $K$ and the second
does the linear combination of them.
- The network can be trained in two stages:
- The number $k$ of hidden units is determined and each unit
$u$ is defined by choosing the values of $x_u$ and
$\sigma_u^2$ that define its kernel function
$K_u(d(x_u,x))$ (e.g., with EM).
- The weights $w_u$ are trained to maximize the fit of the
network to the data using the global squared error
criterion.
- Since the $K_u$ are fixed for the second step it can be
trained with efficient linear function fit methods.
José M. Vidal
.
12 of 18