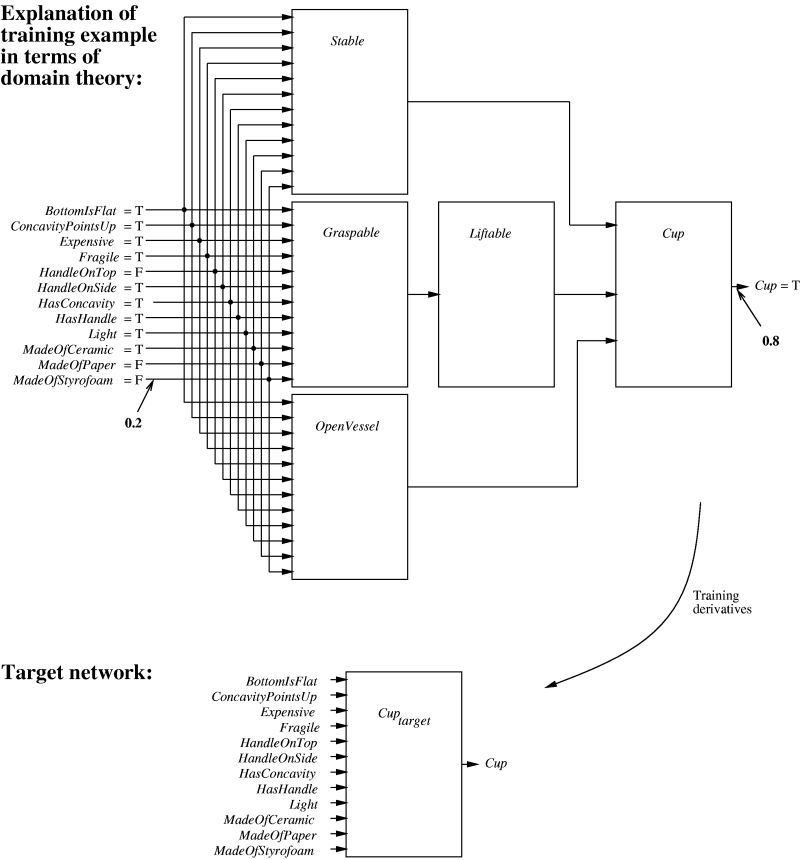
- There is one network for each of the Horn clauses in the domain theory.
- EBNN uses the top network to calculate the partial derivative of the prediction with respect to each feature of the instance. (i.e., how much does the output change as I tweak BottomIsFlat?).
- These derivatives are given to the bottom network which is trained with a variation of TangentProp.