Results
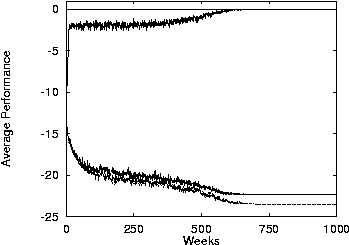
- Performance in leader-follower problem with a worst-case
payoff matrix---the leader maximizes his WL reward when his is
placed in separate subworld from followers.
- The top curve represents perfect constraint alignment in the
initial subworld-assignment (i.e., leader and followers in the
same subworld), the bottom minimal constraint-alignment (i.e.,
leader and followers in different subworlds), and the middle
random subworld assignments.
- There is no macrolearning.
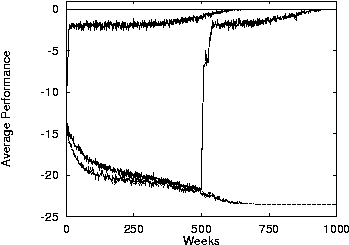
- With macro learning at 500 weeks on the middle curve (random
assignments).
- The random subworld-assignment jumps when macrolearning
happens.
José M. Vidal
.
7 of 13