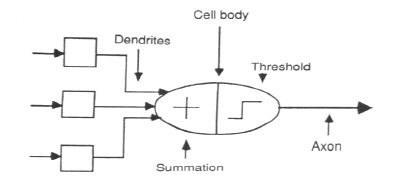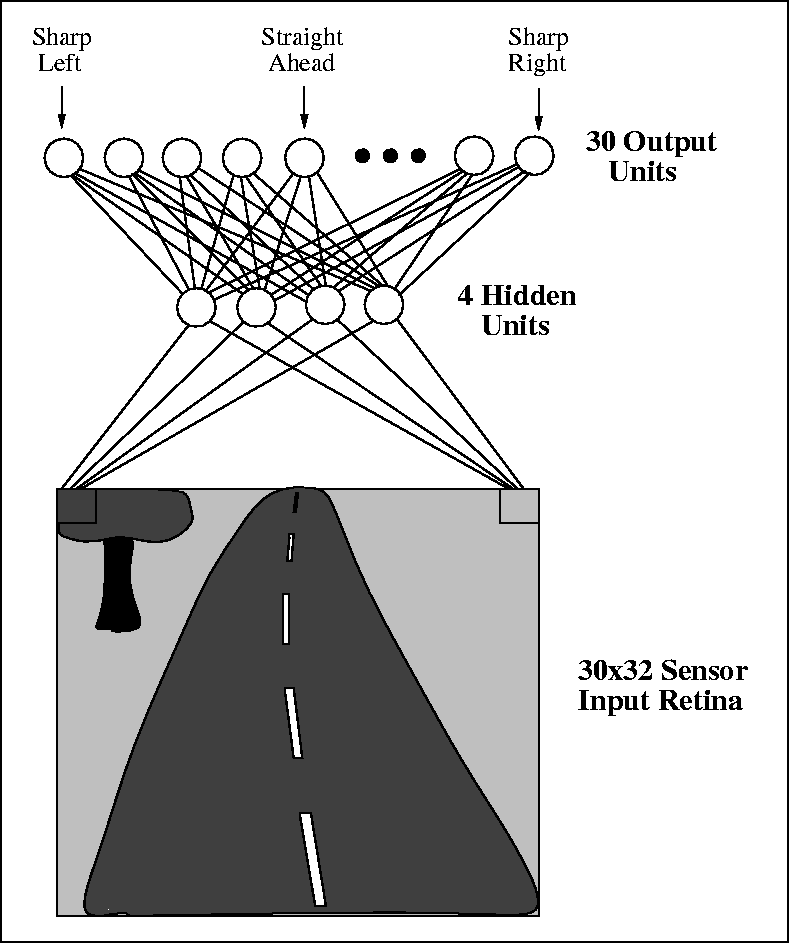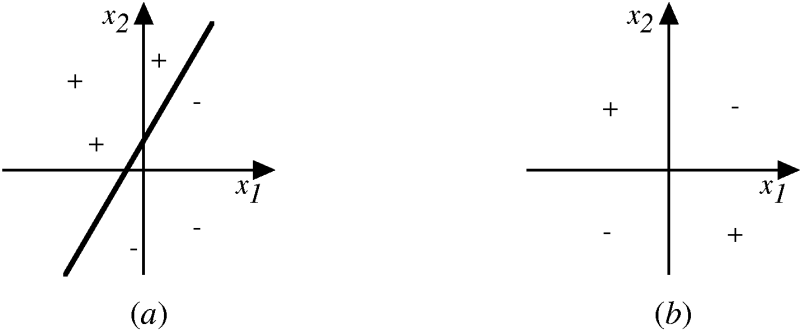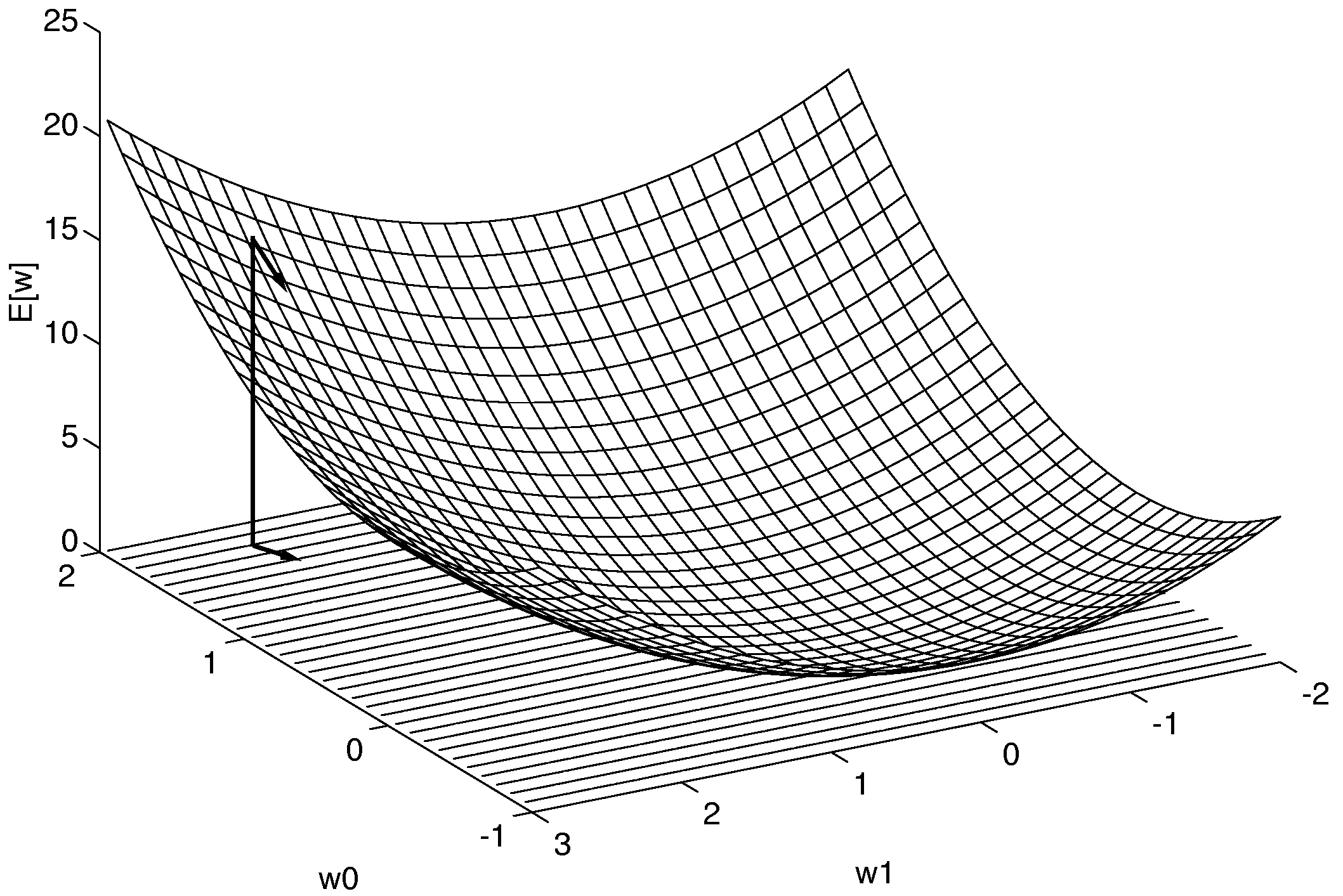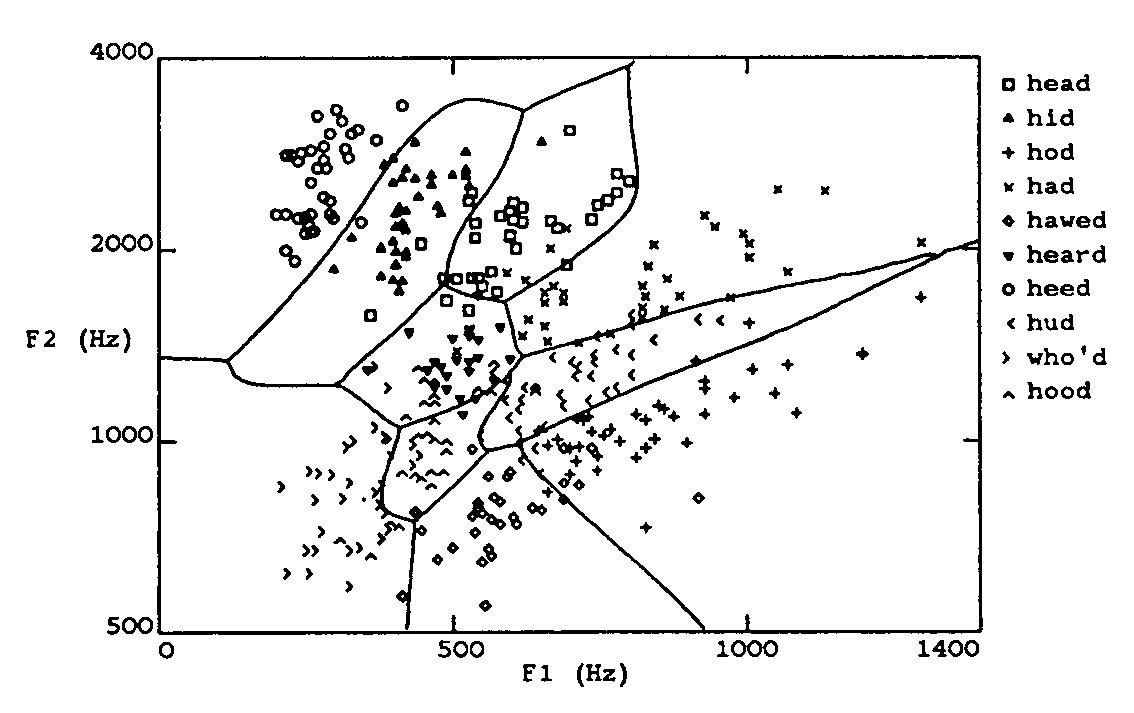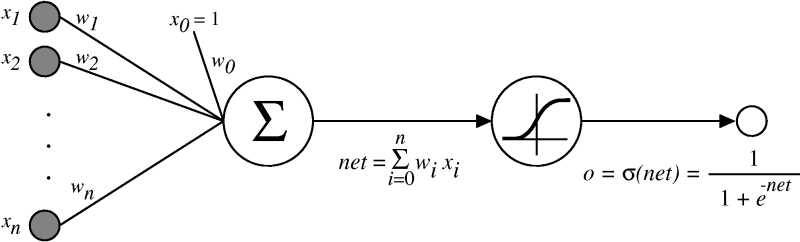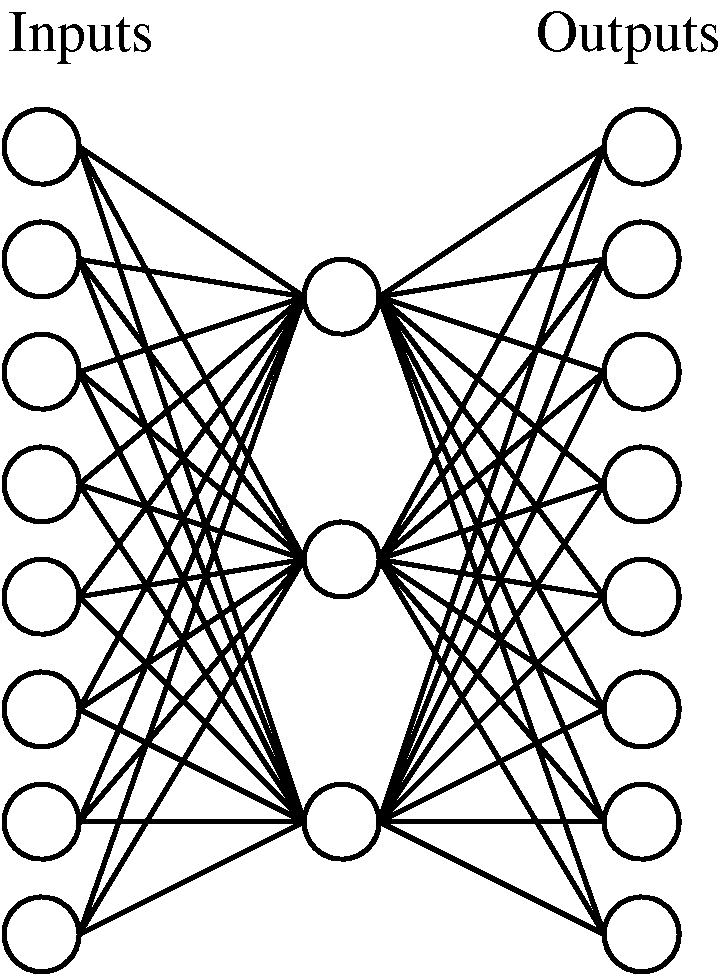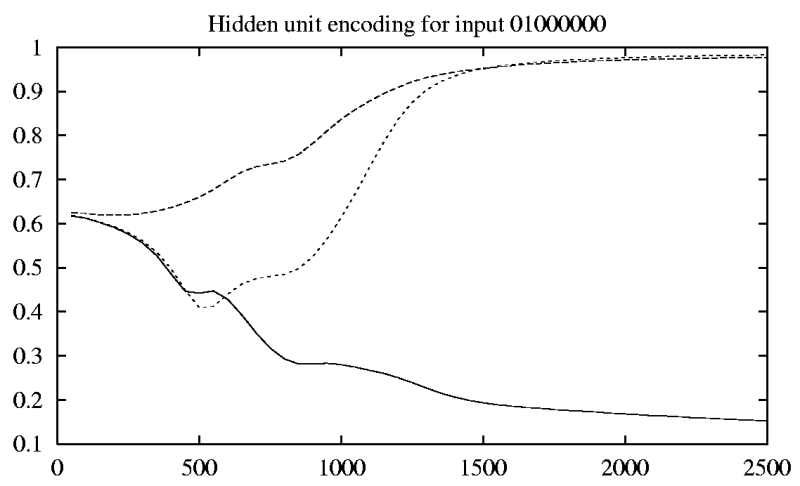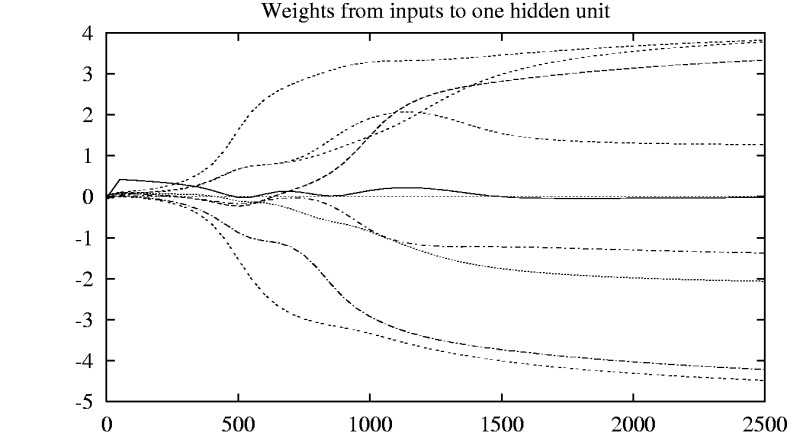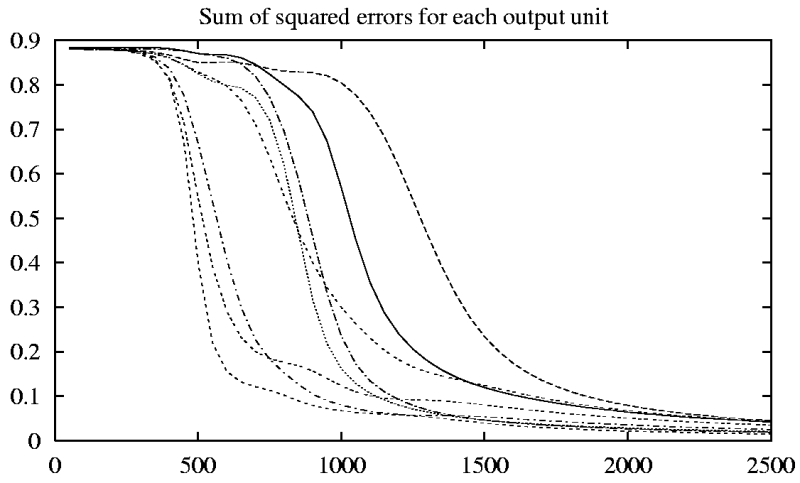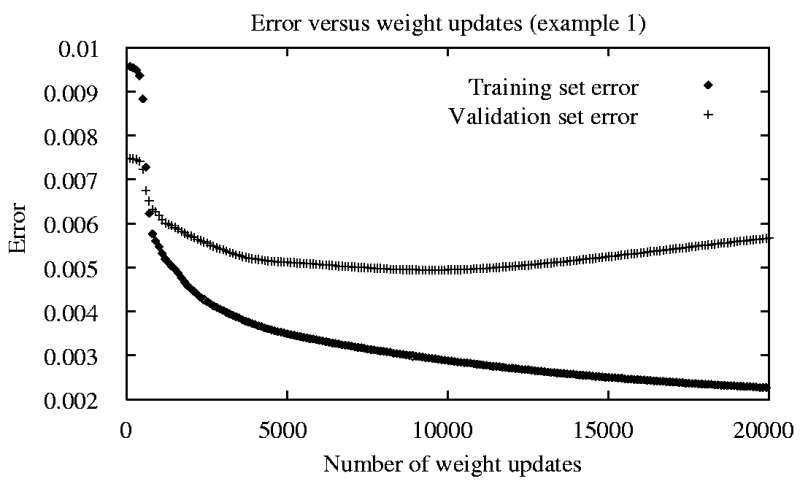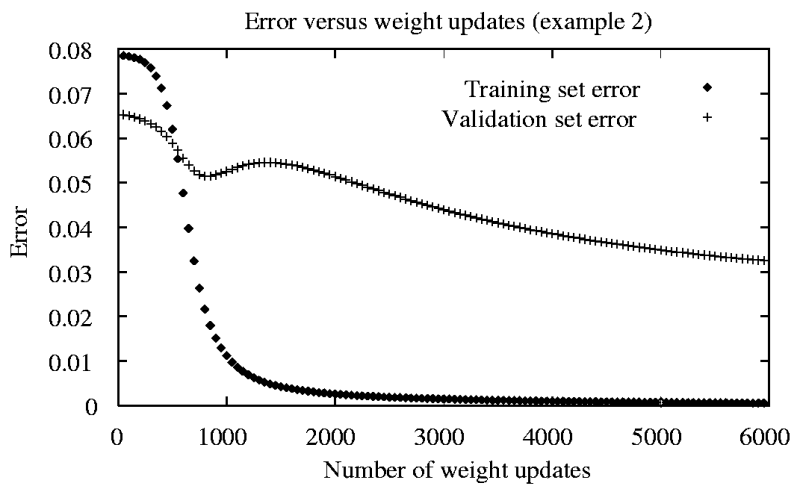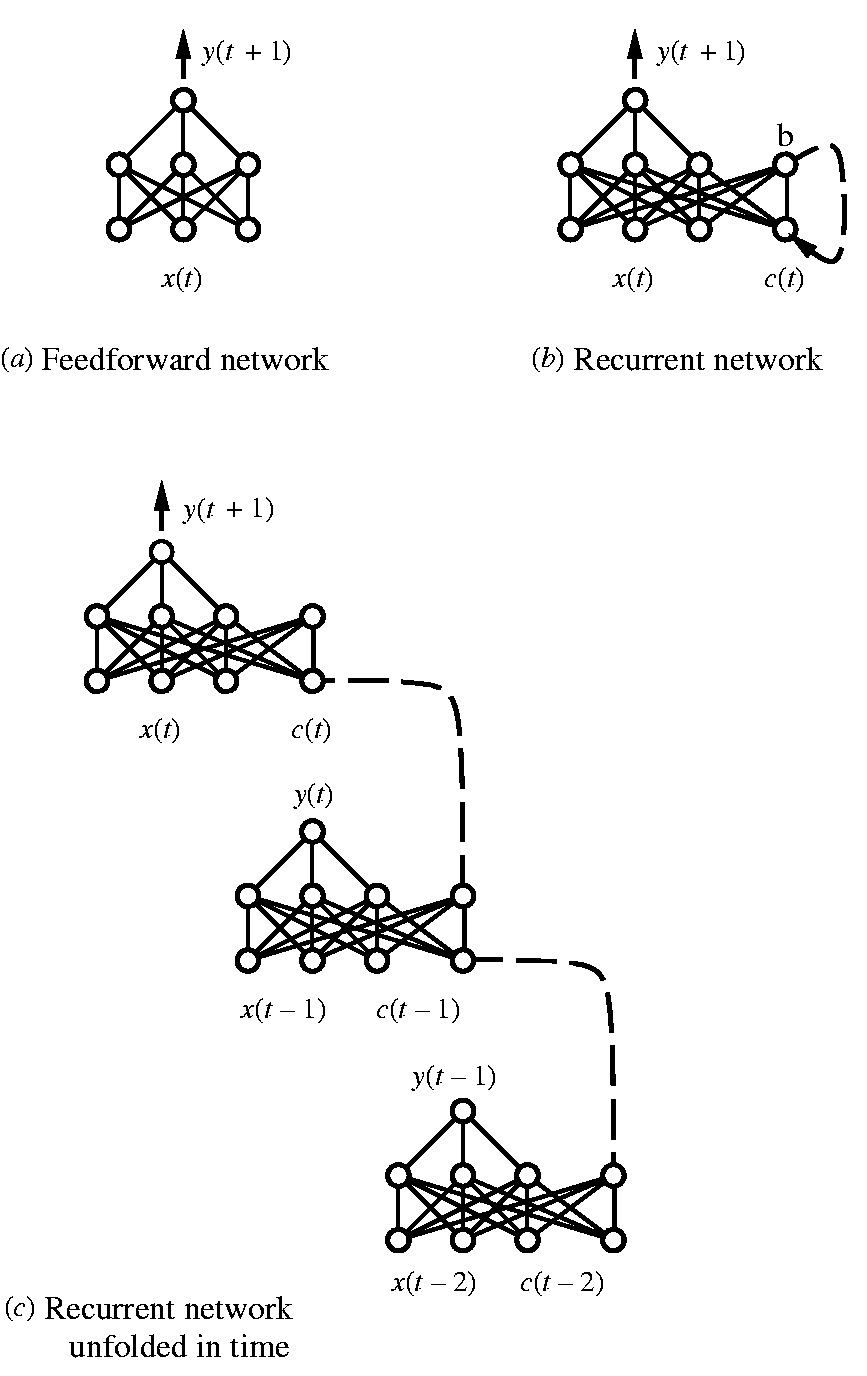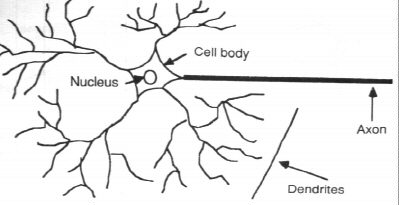
A neuron
- Has about neurons each connected to other neurons.
- Each neuron has inputs which are called dendrites and one output which is called the axon.
- The switching time is about second.
- It takes around second for the brain to recognize an image, which implies about 100 inference steps.
- So, the brain must do some parallel processing on highly distributed data.
- ANNs are not identical to human neurons. They are merely simplistic approximations.