We want a learning method such that:
- Given no domain theory it should be as good as purely
inductive methods.
- Given a perfect domain theory it should be as good as
analytical methods.
- Given imperfect domain theory and imperfect data it should
combine the two and do batter than both inductive and
analytical.
- Accommodate an unknown level of error in training
data.
- Accommodate an unknown level of error in domain theory.
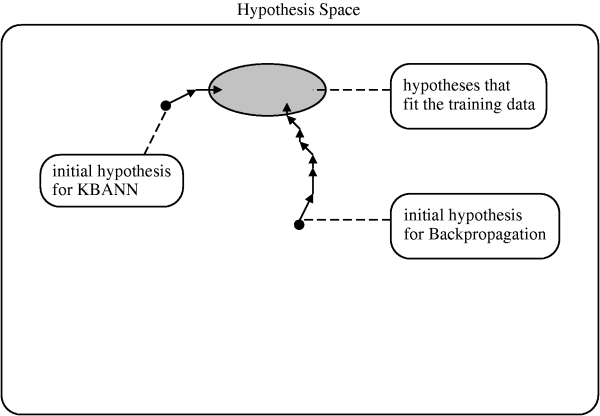
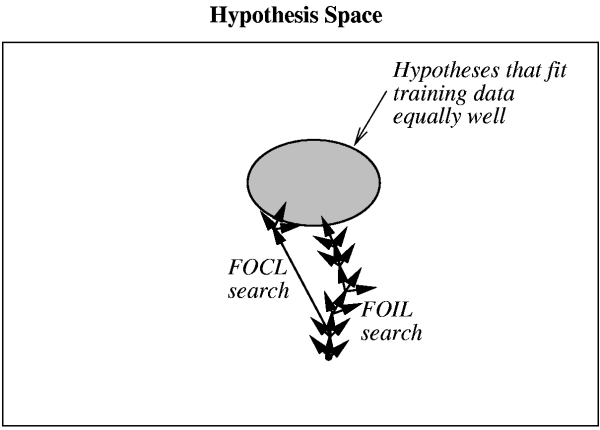
As always, we view the problem as that of search over H where
- H is the hypothesis space.
- O is the set of operators (search steps).
- G is the search objective.
We see that we have several possible approaches:
- User prior knowledge to derive an initial hypothesis from
which to begin the search.
- Use prior knowledge to alter the objective of the
hypothesis space search.
- User prior knowledge to alter the available search
steps.
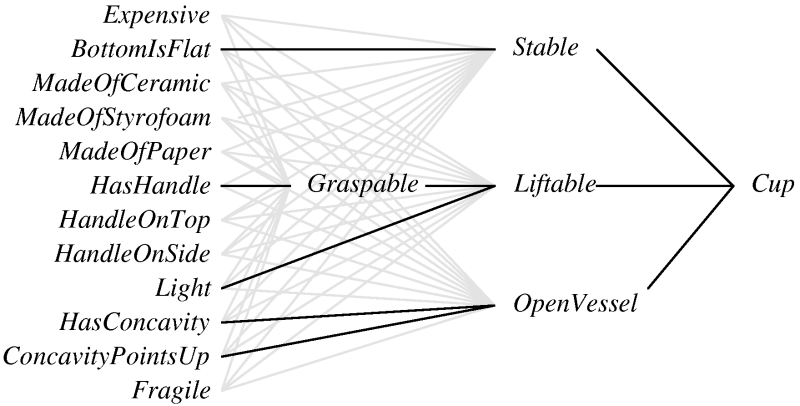
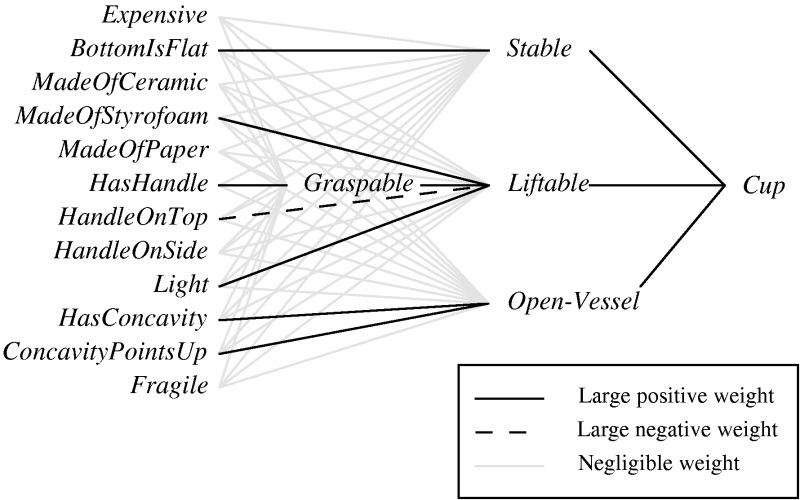
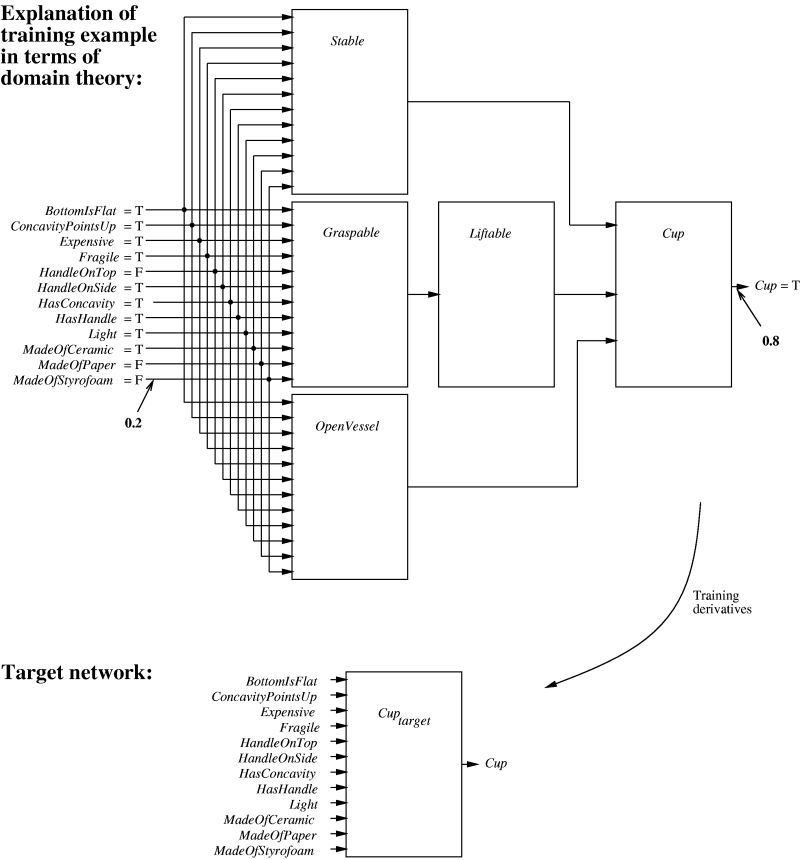
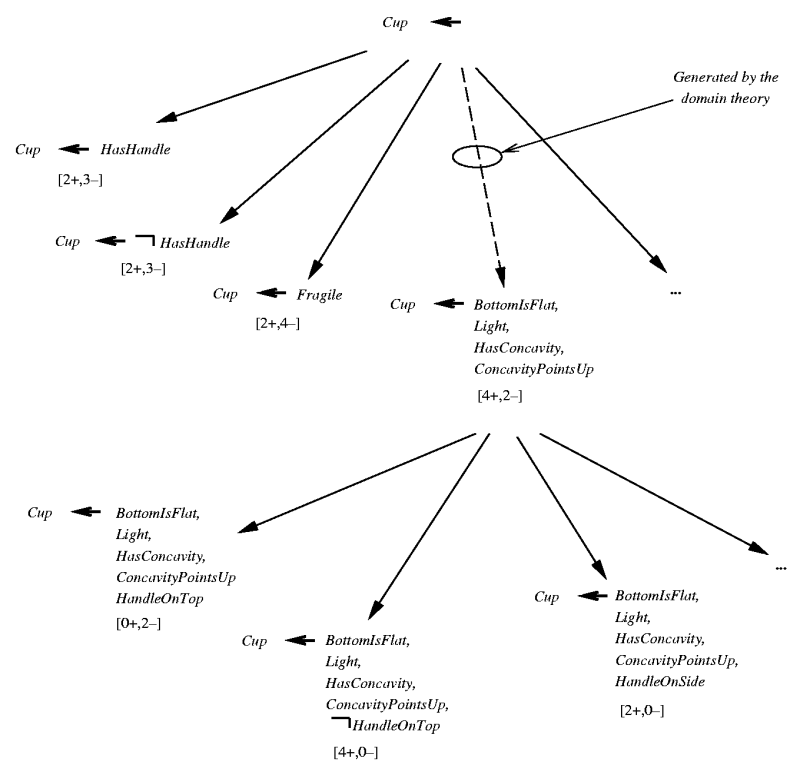
KBANN(domainTheory, trainingExamples)
- for each instance attribute create a network
input.
- for each Horn clause in domainTheory, create a network unit
- Connect inputs to attributes tested by
antecedents.
- Each non-negated antecedent gets a weight W.
- Each negated antecedent gets a weight -W
- Threshold weight is -(n - .5), where n is the number of non-negated antecedents.
- Make all other connections between layers, giving
these very low weights.
- Apply Backpropagation using trainingExamples