This talk is based, in part, on:
Message-passing is the simplest of all models as it is
essentially just a socket abstraction. Client-server models
are by far the most popular application model due in large
part to the fact that most applications seem well suited to
the restrictions of this model. That is, it is often the case
that a service needs to be provided by one machine to other
machines because the machine in question either has a lot more
CPU power than the rest, or a lot more hard drive space, or
access to some special data, etc. Client-server is also easier
to implement since all we need to do is make the server do a
synchronous receive. The idea of making these services
location-independent has been floating around for decades and
implemented in various systems, most notably Jini. It is not
easy to achieve location independence, especially in the
presence of faults (lost messages, broken servers, etc.), so
every implementation needs to make certain concessions on how
often the service search will work versus how long and how
many resources it will take.
Peer-to-peer systems hold the most promise for the development
of robust and agile distributed systems. However, we do not
yet have algorithms that will support their growth. The
problem lies in open p2p systems where all the peers are
selfish agents. These systems require mechanisms that can
align the individual selfishness of the peers with the global
needs of the system. These algorithms are being developed by
researchers in multiagent systems.
Message-oriented middleware adds some often-needed
functionality to the basic message-passing paradigm. These
systems are usually small utility libraries. RPC was the first
departure from message passing. It was the first step in
integrating distributed computation into the programming
language. Unfortunately, the libraries that exist mostly don't
work well with each other so you can only RPC to a similar
host.
The idea of shared tuple spaces was popularized by the Linda
language. Implementing these spaces presents several
problems. The tuple-space needs to be physically distributed
and yet available in its entirety to all the agents, even in
the presence of failures. The searches for a particular tuple
need to be performed by some agent, but we also do not want to
overload any one agent. Finally, read-write permissions might
need to be implemented in these objects. The Linda papers
explain how these were implemented in their systems, but there
exist many algorithms for achieving these goals, all of them,
of course, have different strengths and weaknesses.
Mobile agents have been characterized as a solution looking
for a problem. They do, however, have a place in systems were
communication costs are very high and a lot of computation is
required using the local data. Unfortunately, these type of
constraints do not seem to appear often (or, at all?) in the
real world, so mobile agent systems are still only studied by
academic researchers.
Our goal is something like:
Widget w = new Widget();
w.calculate();
- In order to do achieve this small miracle we need many
things.
- We need a protocol for creating new objects remotely,
invoking methods on them, getting the results back, and deleting
unused objects.
- In order to do this we must send
- Class references
- Object references.
- Method references.
- Method arguments and return values.
- We start with one definition of our widget interface.
interface Widgets {
double getStrenth();
void tickle(int times);
String getWisdom();
}
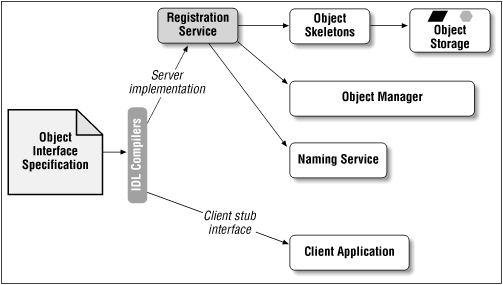
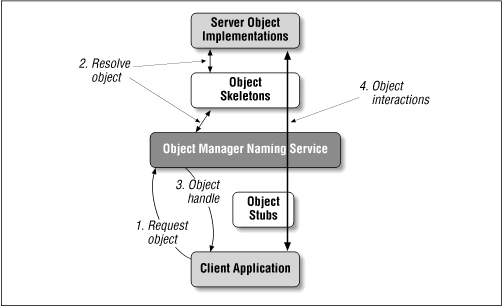
- From this code, we run a program that generates both a stub
and a skeleton.
- The skeleton is placed in the object server, which stands
ready to serve and service copies.
- The stub is placed in the name service and, somehow, finds
its way to the client.
- In CORBA the programs can be written in different
languages and platforms.