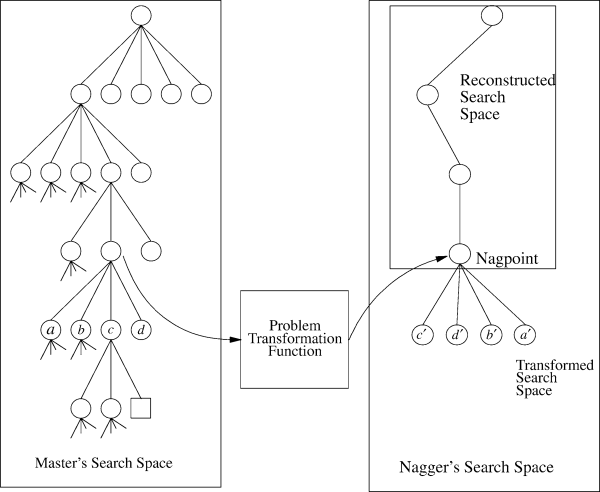
Figure 1: The basic idea behind the nagging algorithms, taken from Segre's paper.
Figure 1: The basic idea behind the nagging algorithms, taken from Segre's paper.
You will implement a nagging strategy to solve the distributed constraint optimization problem using the branch and bound algorithm from Figure 2.12 in our text book.
The nagging idea is described in the following paper:
This paper describes nagging, a technique for parallelizing search in a heterogeneous distributed computing environment. Nagging exploits the speedup anomaly often observed when parallelizing problems by playing multiple reformulations of the problem or portions of the problem against each other. Nagging is both fault tolerant and robust to long message latencies. In this paper, we show how nagging can be used to parallelize several different algorithms drawn from the artificial intelligence literature, and describe how nagging can be combined with partitioning, the more traditional search parallelization strategy. We present a theoretical analysis of the advantage of nagging with respect to partitioning, and give empirical results obtained on a cluster of 64 processors that demonstrate nagging's effectiveness and scalability as applied to A* search, alphabeta minimax game tree search, and the Davis-Putnam algorithm.
The first to note is that the assumptions in nagging are different from those in Chapter 2. Specifically, while the textbook assumes that each variable is an agent, in the nagging algorithm this assumption no longer holds. Instead, your agents all know the complete graph and perform parts of the branch and bound search over arbitrary sets of nodes.
Your first step for this problem set is to implement a centralized branch and bound function which solves the constraint optimization problem. That is, start with one of our existing NetLogo models which already solve the DCOP problem, get rid of the algorithm part and replace it with one function which implements Figure 2.12 from the textbook.
Once you have a centralized function then you can start implementing the nagging strategy by creating a fixed set of worker agents which perform parts of the search. You are free to implement the details of the nagging strategy in the way you think will be best, but there are some specific requirements you should obey:
What we are looking for is a nagging algorithm that
These are really just a wish list. Do the best you can.
YOu can also try to implement Asynchronous Backtracking for graph coloring. There is already an implementation of this algorithm in my netlogo mas page but it does not work anymore under 4.0. It also needs to be updated as it does not use the new links primitives (which should make everything much easier). Note that implementing the hyperesolution rule is also not easy, in fact, I would be happy with just a partial implementation. The current implementation only finds some possible nogoods.
